cuDF pandas 加速器模式
加速 PANDAS
零代码更改
零代码更改加速
利用 pandas 的全部灵活性编写代码。只需加载 cudf.pandas 即可在 GPU 上加速,如果需要,还会自动回退到 CPU。
一个代码路径
针对不同硬件
无论硬件如何,都可以使用单个代码路径进行开发、测试和生产运行。
兼容第三方库
pandas 加速器模式与大多数操作 pandas 对象的第三方库兼容——它甚至可以**在**这些库中加速 pandas 运算。
加速整个 pandas 生态系统
将 cuDF 的速度带给 pandas 用户及其生态系统。借助 GPU,您可以在数据增长的同时继续使用 pandas。
带来 cuDF 的速度
赋能每一位 Pandas 用户
如何使用
此模式在标准 cuDF 包中可用。要使用 cudf.pandas,请在*导入或使用 pandas 之前*通过以下方法之一启用它
要加速 IPython 或 Jupyter Notebooks,请使用以下魔术命令
%load_ext cudf.pandas
import pandas as pd
...要加速 Python 脚本,请在命令行上使用 Python 模块标志
python -m cudf.pandas script.py或者,如果您无法使用命令行标志,则通过导入显式启用 cudf.pandas
import cudf.pandas
cudf.pandas.install()
import pandas as pd
...加速 150 倍,零代码更改
* 标准 DuckDB 数据基准测试 (5GB)
GPU: NVIDIA Grace Hopper, CPU: Intel® Xeon® Platinum 8480C
pandas v2.2, RAPIDS cuDF v23.10 了解更多
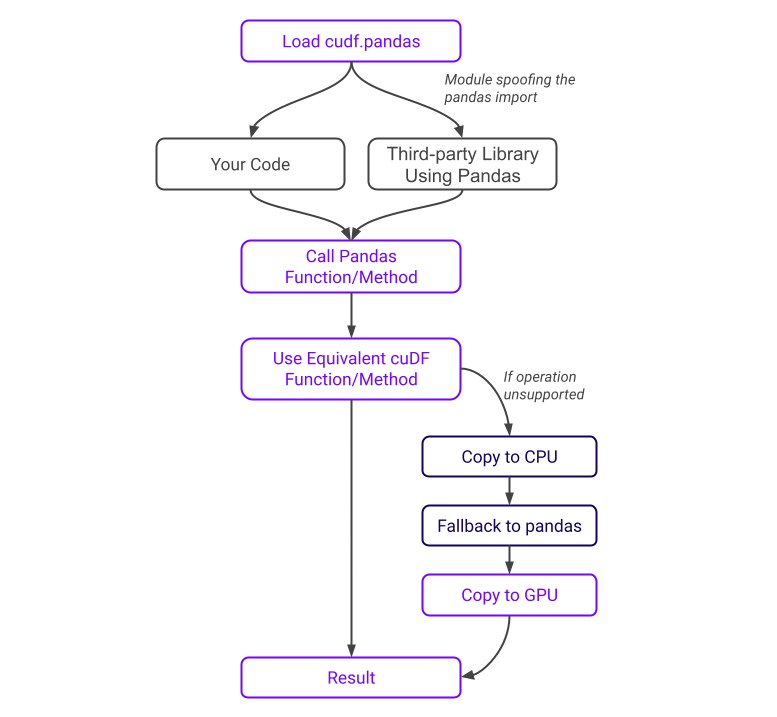
工作原理
底层原理
启用 cudf.pandas 后,import pandas(或其任何子模块)会导入一个魔术模块,而不是“普通”的 pandas。此魔术模块包含代理类型和代理函数
In [1]: %load_ext cudf.pandas
In [2]: import pandas as pd
In [3]: pd
Out[3]: <module 'pandas' (ModuleAccelerator(fast=cudf, slow=pandas))>对代理类型和函数的运算尽可能在 GPU 上执行,否则在 CPU 上执行,并在底层按需同步。这适用于您代码和可能使用的第三方库中的 pandas 运算。
所有 cudf.pandas 对象在任何给定时间都是 GPU (cuDF) 或 CPU (pandas) 对象的代理。运算首先尝试在 GPU 上执行(如有必要,从 CPU 复制)。如果失败,则尝试在 CPU 上执行运算(如有必要,从 GPU 复制)。
使用 cudf.pandas 时,cuDF 的 pandas 兼容模式会自动启用,确保与 pandas 特定的语义(例如默认排序顺序)保持一致性。
执行流程
带来 cuDF 的速度
赋能每一位 Pandas 用户
立即在 Colab 上试用
使用您的 Google 帐号,在支持 GPU 的免费 Notebook 环境中试用 cuDF 新的 pandas 加速器模式,方法是在 Colab 上启动
更喜欢使用自己的 GPU?通过 10 Minutes to cudf.pandas 开始使用,或查看我们的完整 RAPIDS 社区 Notebook 合集
cuDF 的 pandas 加速器模式是 cuDF 包的一部分,可与所有 RAPIDS 库流畅协作。访问 RAPIDS 快速入门,在您喜欢的平台上开始使用任何 RAPIDS 库。
了解更多
cuDF pandas 加速器模式现已正式发布 (GA),可供广泛使用。您可以通过文档和发布博客 了解更多信息
偏好会议演示而非文档?在AI and Data Science Virtual Summit 上了解有关 cudf.pandas 工作原理、我们如何测试它以及我们为何开发它的所有详细信息
想要贡献或分享反馈,请在 GitHub 上联系我们